使用 PyTorch 实现 GoogLeNet
概述
ILSVR 2014 冠军。
对应仓库地址:https://github.com/songquanpeng/pytorch-classifiers
实现细节
Inception Block 中为什么要有三种不同 size 的卷积分支?
不同 size 的 kernel 可能将有助于处理处理多尺度的物体,由网络自行学习是否以及如何使用不同 size 的 kernel。
实际上 PyTorch 的官方实现中 5x5 卷积被替换为了 3x3 卷积,因为当时从 TensorFlow 移植时其用的就是 3x3 卷积。
详见:
- https://github.com/pytorch/vision/blob/master/torchvision/models/googlenet.py#L240
- https://github.com/pytorch/vision/issues/906
Inception Block 中为什么要有一个 Pooling 分支?
Additionally, since pooling operations have been essential for the success in current state of the art convolutional networks, it suggests that adding an alternative parallel pooling path in each such stage should have additional beneficial effect, too.
以上是原论文中的解释,就是说 SOTA 都用,所以我们这里也用了。
卷积层中为什么要设置 bias=False?
两点:
- 对于深层网络,bias 存在与否影响不大,参见此处。
- 另外是因为 PyTorch 的官方实现中用了 Batch Normalization,而 Batch Normalization 会添加 bias 的,所以卷积层不加也无所谓,参见此处。
架构
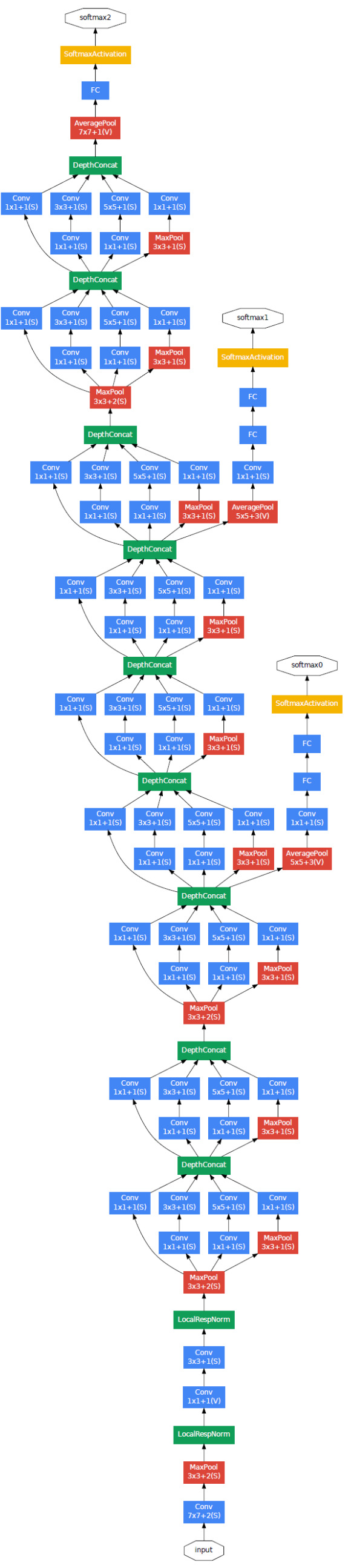
PyTorch 实现
import torch
import torch.nn.functional as F
from torch import nn
class GoogLeNet(nn.Module):
def __init__(self, args):
super().__init__()
self.args = args
assert args.img_size == 224
layers = [
BasicConv(3, 64, kernel_size=7, stride=2, padding=3), # 64x112x112
nn.MaxPool2d(3, 2, ceil_mode=True), # 64x56x56
BasicConv(64, 64, kernel_size=1), # 64x56x56
BasicConv(64, 64 * 3, kernel_size=3, padding=1), # 192x56x56
nn.MaxPool2d(3, 2, ceil_mode=True) # 192x28x28
]
self.sec0 = nn.Sequential(*layers)
layers = [
Inception(192, 64, 96, 128, 16, 32, 32), # 256x28x28 (256=64+128+32+32)
Inception(256, 128, 128, 192, 32, 96, 64), # 480x28x28
nn.MaxPool2d(3, 2, ceil_mode=True), # 480x14x14
Inception(480, 192, 96, 208, 16, 48, 64), # 512x14x14
]
self.sec1 = nn.Sequential(*layers)
self.h0 = InceptionAux(512, args.num_classes)
layers = [
Inception(512, 160, 112, 224, 24, 64, 64), # 512x14x14
Inception(512, 128, 128, 256, 24, 64, 64), # 512x14x14
Inception(512, 112, 144, 288, 32, 64, 64), # 528x14x14
]
self.sec2 = nn.Sequential(*layers)
self.h1 = InceptionAux(528, args.num_classes)
layers = [
Inception(528, 256, 160, 320, 32, 128, 128), # 832x14x14
# Please notice in the official PyTorch implementation, the following MaxPool2d layer's kernel size is 2
# https://github.com/pytorch/vision/blob/master/torchvision/models/googlenet.py#L105
nn.MaxPool2d(3, 2, ceil_mode=True), # 832x7x7
Inception(832, 256, 160, 320, 32, 128, 128), # 832x7x7
Inception(832, 384, 192, 384, 48, 128, 128), # 1024x7x7
nn.AdaptiveAvgPool2d((1, 1))
]
self.sec3 = nn.Sequential(*layers)
self.h2 = nn.Linear(1024, args.num_classes)
def forward(self, x, return_aux=False):
x = self.sec0(x)
x = self.sec1(x)
out0 = self.h0(x)
x = self.sec2(x)
out1 = self.h1(x)
x = self.sec3(x)
out2 = self.h2(x.view(x.shape[0], -1))
if return_aux:
return out0, out1, out2
return out0
class Inception(nn.Module):
""" Inception module with dimension reductions """
def __init__(self, in_channels, out_ch1x1, mid_ch3x3, out_ch3x3, mid_ch5x5, out_ch5x5, out_proj):
super().__init__()
self.b1 = nn.Sequential(BasicConv(in_channels, out_ch1x1, kernel_size=1))
self.b2 = nn.Sequential(
BasicConv(in_channels, mid_ch3x3, kernel_size=1),
BasicConv(mid_ch3x3, out_ch3x3, kernel_size=3, padding=1)
)
self.b3 = nn.Sequential(
BasicConv(in_channels, mid_ch5x5, kernel_size=1),
BasicConv(mid_ch5x5, out_ch5x5, kernel_size=5, padding=2)
)
self.b4 = nn.Sequential(
# ceil_mode – when True, will use ceil instead of floor to compute the output shape
nn.MaxPool2d(3, 1, 1, ceil_mode=True),
BasicConv(in_channels, out_proj, kernel_size=1)
)
def forward(self, x):
out1 = self.b1(x)
out2 = self.b2(x)
out3 = self.b3(x)
out4 = self.b4(x)
out = torch.cat([out1, out2, out3, out4], dim=1)
return out
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super().__init__()
layers = [
nn.AdaptiveAvgPool2d((4, 4)),
BasicConv(in_channels, 128, kernel_size=1)
]
self.conv = nn.Sequential(*layers)
layers = [
nn.Linear(128 * 4 * 4, 1024),
nn.ReLU(inplace=True),
nn.Dropout(p=0.7),
nn.Linear(1024, num_classes)
]
self.fc = nn.Sequential(*layers)
def forward(self, x):
h = self.conv(x)
out = self.fc(h.view(x.shape[0], -1))
return out
class BasicConv(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super().__init__()
# Why bias = False? Two reasons:
# 1. In larger network bias is make no much difference.
# https://stackoverflow.com/questions/51959507/does-bias-in-the-convolutional-layer-really-make-a-difference-to-the-test-accura
# 2. The following BN layer have a bias item.
# https://stackoverflow.com/questions/46256747/can-not-use-both-bias-and-batch-normalization-in-convolution-layers
layers = [
nn.Conv2d(in_channels, out_channels, bias=False, **kwargs),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
]
self.conv = nn.Sequential(*layers)
def forward(self, x):
return self.conv(x)
Links: pytorch-3-googlenet