使用 PyTorch 实现 VGG16
概述
ILSVR 2014 亚军
16 指的是网络中有 16 个需要学习权重的网络层,其中包含 13 个卷积层,3 个全连接层。
总参数数量约 138M(1k 个输出类别时),其中第一个全连接层的参数数量为 512*7*7*4096=102.76M。
(不知道用 1x1 卷积代替全连接层会如何。)
网络的特定是卷积层 kernel 尺寸均为 3,网络前部由几个结构类似的卷积块构成。
这里与 AlexNet 的不同之处在于不再使用 kernel 尺寸为 7 的卷积层,而是堆叠多层的 3x3 kernel 的卷积层, 进而在不损害感受野大小的情况下减少参数量。
卷积块中前面几层(2 或 3)为卷积层,其中首层将输入特征图的通道数翻倍(最大通道数量 512), 其余卷积层保持特征图尺寸不变,最后的最大池化层将特征图尺寸减半(kernel 尺寸为 2,stride 为 2)。
对应仓库地址:https://github.com/songquanpeng/pytorch-classifiers
网络架构
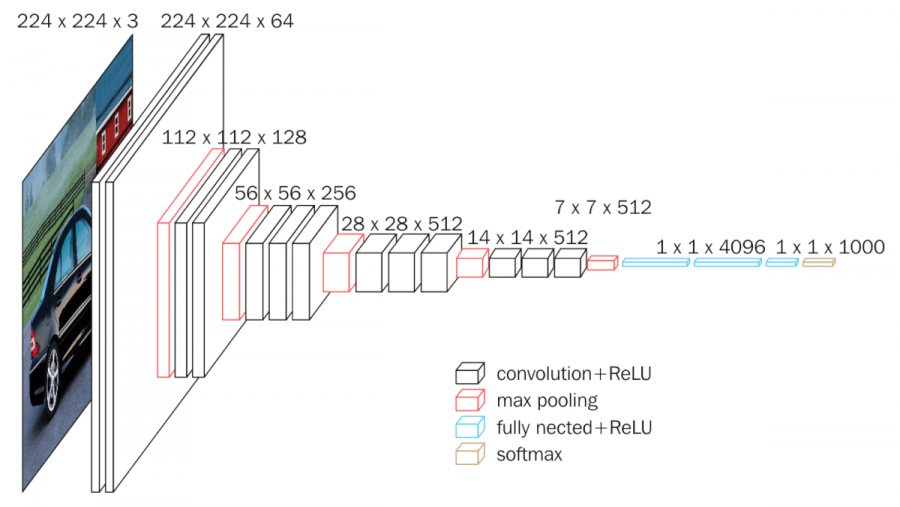
PyTorch 实现
class VGGConvBlock(nn.Module):
def __init__(self, num_conv, in_dim, out_dim, kernel_size=3, stride=1):
super().__init__()
layers = []
for i in range(num_conv):
layers.extend([
nn.Conv2d(in_dim, out_dim, kernel_size, stride, padding=1),
nn.ReLU()
])
in_dim = out_dim
layers.append(nn.MaxPool2d(2, 2))
self.main = nn.Sequential(*layers)
def forward(self, x):
return self.main(x)
class VGG16(nn.Module):
def __init__(self, args):
super().__init__()
self.args = args
assert args.img_size == 224
init_dim = 64
max_dim = 512
layers = [
VGGConvBlock(2, args.img_dim, init_dim), # 64x112x112
VGGConvBlock(2, init_dim, init_dim * 2), # 128x56x56
VGGConvBlock(3, init_dim * 2, init_dim * 4), # 256x28x28
VGGConvBlock(3, init_dim * 4, max_dim), # 512x14x14
VGGConvBlock(3, max_dim, max_dim), # 512x7x7
]
self.conv = nn.Sequential(*layers)
dim_conv = 512 * 7 * 7
dim_fc = 4096
layers = [
nn.Linear(dim_conv, dim_fc),
nn.ReLU(),
nn.Linear(dim_fc, dim_fc),
nn.ReLU(),
nn.Linear(dim_fc, args.num_classes)
]
self.fc = nn.Sequential(*layers)
def forward(self, x):
h = self.conv(x)
y = self.fc(h.view(x.shape[0], -1))
return y
PyTorch 的官方实现的特点
- 全连接层之间有 Dropout(激活函数之后)。
- ReLU 全部都用了 inplace=True(只要不报错就说明计算结果没问题,而且可以略微提高性能)。
- 没有限定死输入图像大小,那全连接层的输入 dim 怎么确定?答案是使用
torch.nn.AdaptiveAvgPool2d(output_size), 其对于任何尺寸的输出都能转到指定的输出尺寸。 - 另外卷积层和其对应的激活函数之间可以选用 BatchNorm2d。
具体参见: https://github.com/pytorch/vision/blob/master/torchvision/models/vgg.py
Links: pytorch-2-vgg16